SYS.STATUS: PUBLIC_BETA
Stop overpaying for
AI Agent inference.
> Route every LLM call to the cheapest capable model.
> Cut agent costs by 40% with zero logic changes.
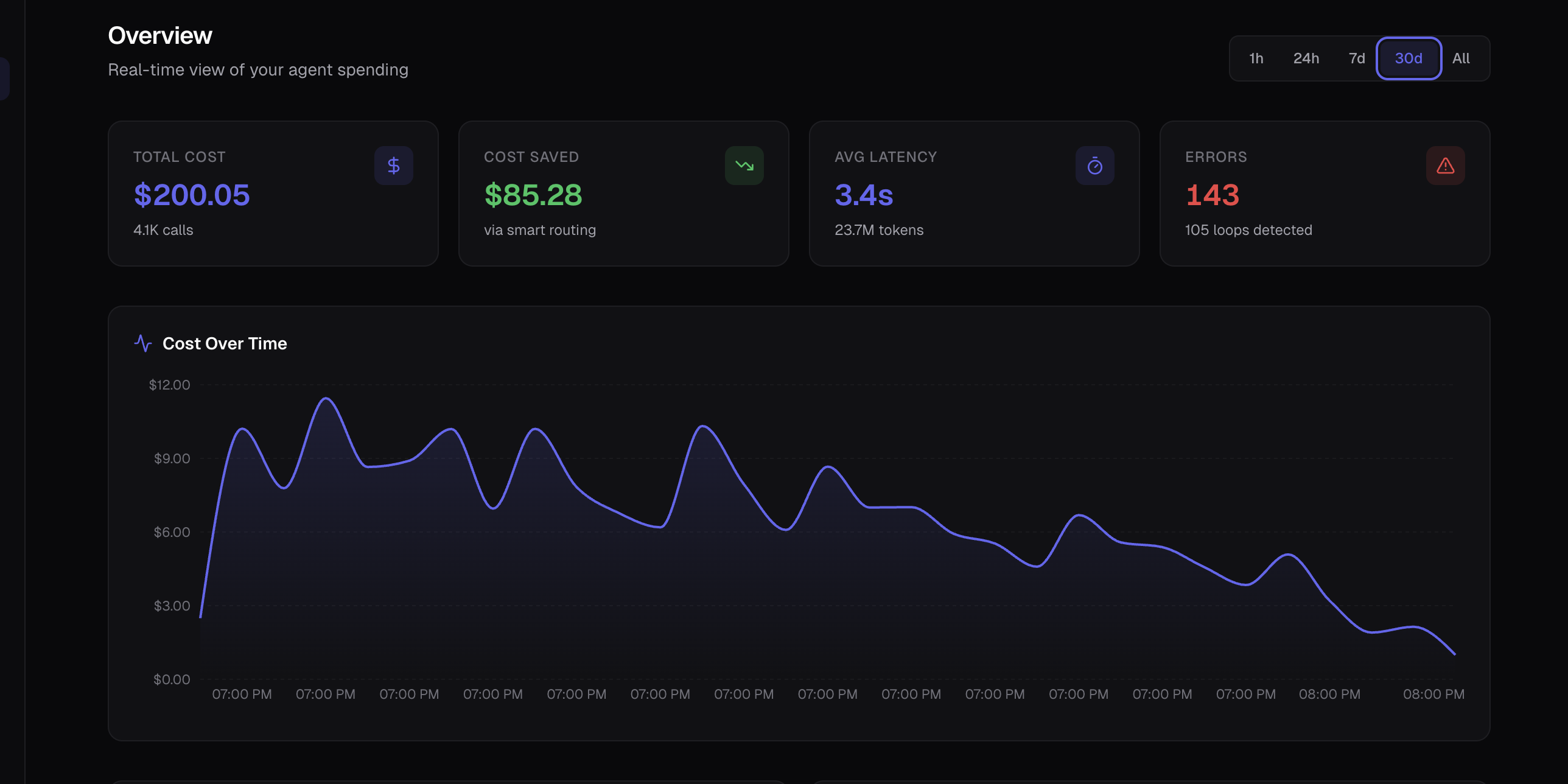
SMART_ROUTING
Automatically routes simple tasks to cheaper models (Haiku, GPT-4o-mini) and hard tasks to smart models.
LOOP_GUARD
Detects runaway agent loops instantly. Escalates to smarter models or halts execution to save your wallet.
REALTIME_TELEMETRY
See exactly which step of your agent is costing the most money. Full visibility into every token.
Drop-in integration.
Works with your existing Python agents. Just wrap your LLM calls and we handle the rest.
- Works with OpenAI, Anthropic, Gemini
- Async & Sync support
- Type-safe Pydantic SDK
- Self-hosted option available
from token_aud.agent import AgentSpend
# Initialize the router
agent = AgentSpend.default()
# Route a task - we pick the model
result = agent.route_call(
step="reason",
messages=[{"role": "user", "content": "..."}]
)
print(f"Saved: {result.cost_saved_usd}")
# Output: Saved: $0.024Ready to stop burning money?
> Join the beta and start optimizing your agent fleet today.